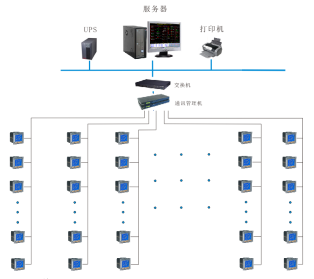
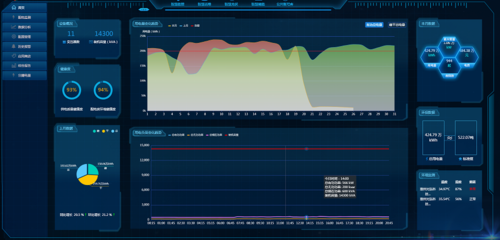
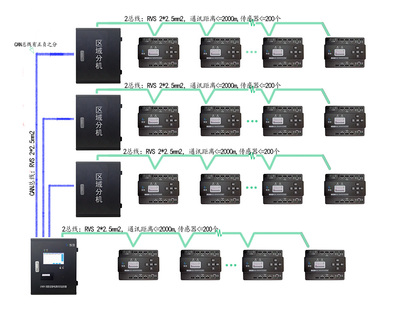
Linux系统管理员必备的12个基础架构监控工具与报警系统开发指南
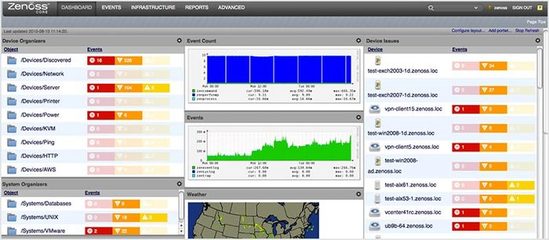
在当今复杂的基础架构环境中,有效的监控和及时的报警是确保系统稳定性和业务连续性的关键。作为Linux系统管理员,掌握一系列强大的监控工具并构建高效的报警系统是必不可少的技能。本文将介绍12个基础架构监控工具,并探讨如何基于这些工具开发报警系统。
一、12个必备的监控工具
- Nagios - 经典的开源监控系统,支持广泛的插件和通知机制,适合监控主机、服务和网络。
- Zabbix - 功能全面的企业级监控解决方案,具备自动发现、实时绘图和灵活的报警配置。
- Prometheus - 专为云原生环境设计的监控和警报工具包,采用拉模型和强大的查询语言PromQL。
- Grafana - 可视化工具,常与Prometheus、InfluxDB等数据源结合,创建直观的监控仪表板。
- Netdata - 实时性能监控工具,提供低延迟的指标收集和精美的Web界面。
- Icinga - Nagios的分支,具有现代化的Web界面和更灵活的配置选项。
- Cacti - 基于RRDTool的网络图形化监控工具,擅长绘制历史数据趋势图。
- Monit - 轻量级的进程监控工具,可自动重启失败的服务,适合单机监控。
- CollectD - 系统统计信息收集守护进程,可将数据发送到多种存储后端如InfluxDB。
- Sysdig - 系统级别的故障排查和监控工具,提供容器可见性和安全监控。
- Elastic Stack(ELK) - 由Elasticsearch、Logstash和Kibana组成,用于日志集中管理和分析。
- Telegraf - InfluxDB的数据收集代理,支持众多输入插件,易于集成到现有监控体系。
二、报警系统的开发
一个高效的报警系统应包含以下核心组件:
- 数据收集层 - 使用上述工具(如Prometheus、Telegraf)收集指标和日志数据。
- 规则引擎 - 定义报警条件,例如CPU使用率超过90%持续5分钟,或服务端口不可达。
- 通知渠道 - 集成多种通知方式,包括邮件、短信(通过Twilio等API)、Slack、钉钉、微信、PagerDuty等。
- 报警聚合与降噪 - 避免报警风暴,对相关报警进行分组和抑制,确保重要报警不被淹没。
- 可视化与仪表板 - 利用Grafana或Kibana创建实时监控视图,帮助快速定位问题。
- 自愈机制 - 结合自动化脚本(如Ansible、SaltStack)或工具(如Monit),在检测到特定问题时自动执行修复操作。
三、实施建议
- 分层监控:从基础设施层(服务器、网络)到应用层(服务、数据库)进行全方位监控。
- 黄金信号:重点关注延迟、流量、错误和饱和度四个关键指标。
- 测试报警:定期测试报警通道的有效性,确保在真实故障时报警能及时送达。
- 文档化:为每个报警规则编写文档,说明触发条件、影响范围和应急处理步骤。
四、
构建监控和报警系统是一个持续迭代的过程。Linux系统管理员应根据实际环境选择合适的工具组合,并不断优化报警策略,以实现从被动响应到主动预防的转变。通过上述工具和方法的有效应用,可以显著提升系统的可靠性和运维效率。
如若转载,请注明出处:http://www.hnyc360.com/product/92.html
更新时间:2026-06-19 19:55:25